这篇博客我们来看一下何凯明老师的掩码自编码器这篇工作,正式介绍之前先回顾一下上一篇介绍ViT的博客。之前提到ViT将原始的Transformer不作过多的修改、直接应用到视觉任务中,原论文中使用图像分类作为目标任务,其中详细描述了怎样对图像进行处理从而匹配Tranformer模型,在文章的最后作者提出了几个观点,值得注意的有两点,一是当时的工作只讨论了图像分类任务,而视觉中的分割、检测任务还没有被探索,二是作者简单尝试了自监督预训练策略,虽然比其他自监督方法更好,但效果不如监督学习策略,考虑到图像标签数据的规模有限,未来还是应当探索ViT用于自监督预训练。而MAE(Masked AutoEncoder)就相当于回答了ViT论文中最后提出的这两个问题,使用自监督预训练方法完成目标检测和分割等下游任务,并且最终的效果可以超越监督学习预训练方法。
下面的介绍中采用和之前的逻辑,首先对论文、模型结构进行简介说明,然后梳理一些面试中常见的问题,最后看一下具体的代码实现(Talk is cheap, show me the code ^_^)
摘要
这篇论文展示了掩码自编码器(masked autoencoders, MAE)是视觉任务中的灵活的自监督学习器。MAE思路很简单:对输入图像的patches序列随机掩码(遮挡),然后尝试重建出这些被遮挡的像素。其中有两个关键的设计,首先作者提出了一个非对称的encoder-decoder结构,只使用可见的patches(原patches序列的子集)训练encoder,接着轻量的decoder根据潜在表征(即encoder的输出)和mask tokens(下文详细介绍,这里理解为是可学习的参数)重建出原始图像。另一个重要设计是作者使用非常高的遮挡率,例如75%(即只能看到原始图像中1/4的信息),构建出图像重建这样的自监督学习任务。将这两个设计结合在一起,就可以高效且有效地训练大模型(因为遮挡了原始图像中3/4的数据,所以计算量大大降低,并且这种设计会引导模型学习图像中的高级特征,所以最终的性能也得到提升)。作者的设计允许学习泛化好的高容量模型,例如使用原始的ViT-Huge模型、只使用ImageNet-1K数据训练就可以实现最好的精度。迁移到下游任务时也好过监督学习预训练方法,并且有机会进一步扩展。
引言
深度学习中已经可以看到模型的能力和容量呈爆炸式增长。得益于硬件设备的快速发展,当前的模型可以很容易地在百万级别的图像上实现过拟合,并且开始要求亿级别的数据来喂给模型,但是现实中难以获得亿级别图像的标签。(数据非常多但标签太有限,所以应当探索自监督学习方法,让模型主动学习图像中的特征)
在NLP领域中,对大规模数据的需求已经通过自监督预训练方法解决。例如GPT中使用自回归语言建模,而BERT使用掩码自编码(masked autoencoding)方法,这些实现思路可以归纳为:随机删除数据中的部分内容,让模型通过学习来预测被删除的部分。这些方法允许训练包含千亿参数的、泛化性好的NLP模型。
masked autoencoders是一个更加通用的去噪自编码器,其在视觉任务中也通用。事实上,视觉任务中对这个方法的探索比BERT更早,然而尽管BERT取得成功后涌现出很多在视觉上进行探索的研究,但是视觉中的autoencoding方法的进展落后于NLP。因此作者设问:是什么造成了masked autoencoding方法在视觉和语言中的不同?下面作者从三个方面尝试给出答案:
- 视觉中主流的CNN模型不适合进行mask、位置编码等操作;过去很长一段时间中CNN在视觉任务中占主导地位,卷积操作会对临近区域进行计算,因此不适合在此基础上直接进行mask或者位置编码的操作。(读者可以思考一下把原始图像中的3/4的数据删除之后再做卷积操作会得到什么效果^_^)不过ViT的出现使得将上述操作后的图像输入网络计算成为可能。
- 语言和图像中的信息密度不同;语言作为人类生成的信号有高度的语义和信息密度。训练一个模型、只需要预测句子中少量的缺失单词,仍然可以使得模型对语言产生深刻的理解。但是图像恰好相反,例如图像中如果缺失了一小块仍可以通过临近的图像块推导出来,导致模型难以学到深层语义信息(只能学到一些表面的纹理、线条等底层特征)。为了解决这个问题并且引导迫使模型学习有意义的高级特征,作者使用了一个非常简单的策略:使用较高的比例对随机patch进行mask操作。这个方法可以大幅减少图像中的冗余信息,在此基础上进行图像重建任务可以获得除了底层图像特征以外的、对图像的深度理解。
- 自编码器中的解码器设计;autoencoder中的解码器应当将潜特征重构为网络输入,重建文本和图像时骑着不同的作用。视觉任务中解码器需要实现像素级重建,因此输出的时低级语义特征。而在语言任务中,解码器只需要预测出缺失的单词(其包含丰富的语义信息)。虽然BERT中使用的解码器很简单(一个MLP),但是作者发现对于图像来说解码器起着从学习到的潜表征中识别语义信息的重要作用)。
基于上面的分析,作者设计了一个简单、高效、可扩展的、用于视觉表征学习的masked autoencoder形式。作者设计的MAE会对输入图像的patches序列随机掩码,并且从像素空间中重构出缺失的patches。本质是一个非对称的encoder-decoder形式,encoder只会处理可见的patches子集(删除了mask的patches),轻量的解码器根据潜表征(也就是编码器的输出)和 mask tokens重构出原始图像。将 mask token添加到轻量的解码器中可以减小计算开销。
在这样的设计下,使用比较高的mask比例可以实现双赢:一方面输入编码器的数据更少可以提升训练效率,另一方面引导模型跳出底层特征、学习高级语义特征。这可以使得预训练时间减少3倍以上,同时减小存储开销,那么使得MAE可以非常容易地被扩展为大模型。
MAE可以学习到泛化性很好的高容量模型,使用MAE预训练策略,在ImageNet-1K数据上可以训练ViT-Large/-Huge这样的data-hungry模型,同时泛化性得到提升。使用原始的ViT-Huge模型,在ImageNet-1K数据上可以实现87.8%的精度,优于之前所有只使用ImageNet-1K数据的结果。除此之外作者在目标检测、实例分割和语义分割任务上通过迁移学习进行验证,在这些任务中,作者的预训练方法都优于监督式预训练,同时更重要的是通过扩大模型规模可以看到更好的性能。这些观察使得视觉任务和NLP中自监督预训练方式对齐,并且有望得到进一步探索。
讨论与总结
具有良好规模的简单算法是深度学习的核心。NLP中使用自监督学习方法实现,而在过去的视觉任务中主要使用监督学习的预训练方法而不是自监督学习。在这篇论文中作者通过ImageNet和迁移学习发现自编码器——和NLP中使用的技术十分相似的自监督方法——可以实现良好的扩展。(这里我理解的“扩展”是不局限于某一种特定的任务,可以处理广泛的视觉任务例如分割、检测等)于是自监督学习在视觉中的应用跟上了NLP领域的步伐。
另一方面作者发现了图像和语言是不同的自然信号,并且设计模型时应该仔细考虑两者之间的不同。在mask操作中,选择随机mask图像patches,而不是删除图像中的目标。同样MAE是像素级重建,不是语义级重建。另外MAE可以实现复杂的、整体的重建,表明其可以学习许多视觉语义信息,作者认为这是由于MAE中丰富的隐表征实现的。
相关工作
掩码语言建模:和自回归方法已经在NLP领域中取得了成功(例如BERT、GPT)。这些方法保留一部分输入并且尝试训练模型去预测缺失的部分,实验表明这些方法扩展性好,并且可以推广到多种下游任务。
自编码:是经典的学习表征的方法,它有encoder从输入中学习潜在表征、decoder用于重建输入。例如PCA主成分分析和k-means都属于自编码器。去噪自编码器(Denoising autoencoders,DAE)是一类为输入添加噪声、再去噪重建的一系列自编码器,其中不同的操作(例如对像素进行mask、删除颜色通道等)都被看作广义DAE,而这篇论文中的MAE是DAE的一种,但和传统的DAE有不同的实现方式。
掩码图像编码:通过掩码操作学习图像中的表征。受到NLP中成功实践的启发,最近一些相关的方法都基于Transformer。例如iGPT处理像素序列并且预测出缺失的像素。ViT中使用预测masked patch进行自监督学习。
自监督学习:在视觉领域中引发了很多关注,主要关注的是在预训练阶段中的不同上下文任务。对比学习很流行,主要是通过建模两张或者多张图像的相似性和不相似性。对比学习和相关方法都需要依赖数据增强技术。而自编码器是另一个不同的方向来实现自动的特征学习。
方法
MAE是一个简单的自编码器,从给定的部分观察中重构出原始信号。和常见的做法相同,作者的编码器用来从观察的数据中学习潜在表征,解码器用于从潜在表征中重建原始的输入数据。和经典自编码器不同的是,MAE是非对称的设计,编码器只处理部分信号,而解码器从潜在表征和 mask token中重构完整的原始信号。模型示意图见下:
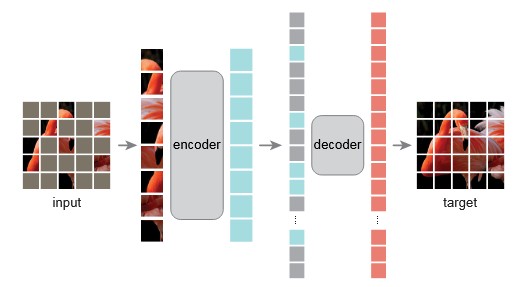
Mask部分,和ViT的操作相同,将原始图像切分为规整的、不重叠的patches。接着从中随机采样子集、将其余未被采样的进行mask操作(也就是移除)。作者的采样策略很直接:使用均匀分布随机采样(防止潜在的中心偏差)。
随机采样使用了一个很高的mask比率(也就是patches的移除率),删除大量冗余信息,从而使得模型难以从附近patches中重建图像、迫使模型学习图像的语义特征。除此之外,删除图像中大量数据后,可以加快训练效率、减少内存占用,从而为后面高效编码器提供了基础。
MAE的编码器使用ViT,但是只处理可见的、unmasked的patches,并且会对patch添加线性映射并加上位置编码,接着通过一系列transformer块得到输出,这个过程中没有输入masked的patches。由于删除了图像中的大量数据因此训练速度更快。
MAE解码器的输入是全集tokens,包括两类数据:潜在表征(也就是编码器的输出)、mask tokens(全局共享的、可学习的向量,用于代表masked patches的信息)。在输入解码器之前,为所有的tokens添加位置掩码信息,否则 mask tokens无法获得其在图像中的位置信息。解码器的设计是另一系列的Transformer模块。
需要注意的是解码器只在预训练时被用于图像重建,推理阶段会设计特定的下游任务的模型头,因此编码器和解码器的设计是独立的。作者在多个小的解码器(比编码器更窄、更浅)上进行了实验。把全集patches交给轻量的解码器处理,可以大大减少预训练时间。
重建目标:MAE需要通过对masked patch进行像素级预测来实现输入的重建。解码器输出的每个元素都是表示一个patch的像素值向量。解码器的最后一层是线性投影层,其输出通道数等于patch中的像素数。解码器的输出会通过reshape操作得到重构的结果。损失函数使用像素级的均方差损失,另外只会在masked patches的位置上计算(和BERT一致)。
简单实现:MAE的预训练可以被高效实现,同时不需要额外的特殊操作。首先生成每个输入patch的token(经过线性投影层后加上位置编码),接着随机打乱patched并且根据masking ratio移除其中的后部分。得到的token子集输入到编码器中。在编码器之后会给encoded patches添加 mask tokens序列,恢复tokens全集的顺序、添加位置编码、然后输入到解码器中。其中只需要可以忽略不记的额外开销,因为shuffing和unshuffing操作非常快。
实验
原论文中的实验非常详尽,这里只选择几点简单描述,感兴趣的读者可以自行查阅原文^_^
- masking ratio:过低或者过高时模型的性能都比较差,需要权衡(ratio较高时,提供的信息不足;较低时,模型会倾向学习低级语义特征);
- 编码器处理
mask token,模型性能下降,作者认为可能由于mask token最初都是随机数据,反而影响编码器提取特征; - mask操作中的采样策略:对比了方法中的随机均匀采样、分块采样、网格采样;
面试常见问题
(注:下面的回答是笔者个人理解,如果有问题欢迎指出交流^_^)
1.MAE的核心思想是通过掩码图像块并重建像素进行自监督学习。为什么论文中选择极高的掩码率(如75%)?这与BERT中的掩码策略(15%)有何本质区别?
在视觉任务中和语言任务中使用不同的掩码率,主要是图像和语言的信息密度不同,语言具有很高的语义密度,只需要对部分词进行掩码就能使得模型学习到有效的语言特点,但是图像中包含非常多的冗余信息,如果掩码率较小,可以根据临近patches推导出掩码patch的数据,导致模型只能学到低级语义信息,而无法学到图像的通用特征。虽然MAE和BERT中的掩码率不同,但本质上都是引导模型学到数据的高级特征,提高模型的特征表示能力。
2.MAE的编码器仅处理未被掩码的图像块,而解码器需要同时处理可见块特征和掩码块占位符。这种非对称编码器-解码器结构的设计动机是什么?如何避免计算冗余?
编码器仅处理没有被掩码的图像块,可以使得编码器计算效率更高、内存占用更少,而解码器的设计非常轻量,将全集patches输入解码器可以提升模型计算效率;另外原论文中作者对比了将掩码块占位符输入到编码器的实验,但由于占位符最开始都是随机初始化的数据,反而影响编码器的特征提取,从而使得模型性能下降。
3.论文中提到解码器是“轻量级”的,具体体现在哪些方面?轻量化解码器对模型训练和下游任务迁移有何影响?
解码器相比编码器更浅、更窄。由于解码器需要处理patches全集数据,将其设计轻量化可以加快模型训练效率,同时解码器和编码器的设计独立,使得迁移学习时无序改动编码器、只需要设计额外的任务头即可。
4.MAE在重建像素时,如何处理不同图像块之间的位置信息?位置编码在编码器和解码器中的作用是否一致?
在将 mask tokens和编码得到的潜表征输入解码器之前,会经过unshuffle和添加位置编码,这样使得 mask tokens可以获得其在图像中位置的信息。编码器中的位置编码更侧重于为输入的图像patch添加位置信息(帮助模型理解空间关系),但是解码器中更多的是给 mask tokens添加位置信息(确保重建时空间对齐)。
5.MAE的掩码块占位符(mask token)是全局共享的可学习参数。如果为每个掩码块分配独立的参数,可能会引入什么问题?
为每个掩码块分配独立的参数,可能会影响模型的训练速率,难以收敛,另外可能导致 mask token训练不充分,学习不到好的参数表征。
6.在消融实验中,随机掩码(random masking)相比网格掩码(grid masking)提升了模型性能,这反映了MAE对图像理解的何种能力?
网格掩码易集中于图像中心,而随机掩码均匀分布,迫使模型学习全局结构。随机掩码会破坏连续区域,任务更难,防止模型通过插值推测出mask patch的信息,增强语义特征学习的能力。
7.论文指出MAE在ImageNet-1K上训练ViT-Huge模型能达到87.8%的准确率。这一结果相比监督学习的ViT有何突破性?背后的关键因素是什么?
MAE的成功代表了自监督学习预训练策略优于监督学习策略,不再依赖数据标签,另外非对称的设计和高mask ratio允许模型规模更大;可能与MAE的自监督预训练策略和比较高的mask ratio等有关,使得模型正确学习到了图像特有表征。
8.MAE在下游任务(如目标检测、语义分割)中的迁移学习表现优于监督预训练模型,如何解释这种泛化能力的提升?
MAE的好的泛化性可能来自其在大规模数据上使用自监督预训练策略,通过设计非对称的encoder-decoder结构、为图像设计恰当的mask ratio、学习 mask tokens等,引导模型学习到图像中的通用特征,而监督学习中是类别特异性特征;除此之外MAE可扩展为大规模网络结构,模型容量提升。
代码实现
接下来看一下代码实现,选择官方实现来介绍。
先来看一下模型前向计算的过程,首先经过encoder得到浅特征 latent、掩码 mask和恢复索引 ids_retore,接着输入到解码器中得到像素级重建结果,最后只在mask patch部分计算图像重建损失。
def forward(self, imgs, mask_ratio=0.75):
latent, mask, ids_restore = self.forward_encoder(imgs, mask_ratio)
pred = self.forward_decoder(latent, ids_restore) # [N, L, p*p*3]
loss = self.forward_loss(imgs, pred, mask)
return loss, pred, mask
接下来看一下encoder的forward过程,
def forward_encoder(self, x, mask_ratio):
# embed patches 打patch并且进行线性embedding
x = self.patch_embed(x)
# add pos embed w/o cls token,添加位置掩码
x = x + self.pos_embed[:, 1:, :]
# mask:0-1值记录哪些patch被保留
# ids_restore: 记录打乱后的patch顺序
# x的原始顺序被shuffle
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# append cls token
# class_token,用于图像分类任务,添加位置掩码
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
# 拼接class_token用于分类任务
x = torch.cat((cls_tokens, x), dim=1)
# apply Transformer blocks,输入编码器
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x, mask, ids_restore
接着来看一下 x, mask, ids_restore = self.random_masking(x, mask_ratio)这里怎样进行随机mask操作的。
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio)) # 计算保留的patch个数 = 总的patch * (1 - mask_ratio)
noise = torch.rand(N, L, device=x.device) # 生成[0, 1]之间的随机数,根据随机数的排序来shuffle
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1) # 用于恢复索引
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep] # 只保留len_keep个元素
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D)) # 只使用随机选择得到的token
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore
# [batch_size,unmasked_token_nums, dim],保留下来输入网络
# [batch_sz, all_pathch_nums],使用0-1值记录了mask的位置
# [batch_sz, all_pathch_nums],记录打乱之后的patch顺序
可以举一个简单的例子说明一下这个计算过程,假设输入数据 x已经经过 patch_embedding操作,得到 [1,9,6](假设 batch_size=1,将图像切分为9个块,每个 patch使用 6维数据表示,掩码率 mask_ratio=0.75,假设 x数据为:
tensor([[[0., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 1.],
[2., 2., 2., 2., 2., 2.],
[3., 3., 3., 3., 3., 3.],
[4., 4., 4., 4., 4., 4.],
[5., 5., 5., 5., 5., 5.],
[6., 6., 6., 6., 6., 6.],
[7., 7., 7., 7., 7., 7.],
[8., 8., 8., 8., 8., 8.]]])
计算 int(num_patches * (1-mask_ratio))得到结果为 2,代表只会向编码器输入 2给原始图像patches。
接着通过生成随机数来实现shuffle操作,
>>> noise = torch.rand(N,L)
>>> noise
tensor([[0.9750, 0.5765, 0.0854, 0.9345, 0.4820, 0.3222, 0.1395, 0.3631, 0.8681]])
>>> noise.shape
torch.Size([1, 9])
按照维度进行排序,得到每个位置元素在序列中从小到大的顺序:
>>> ids_shuffle = torch.argsort(noise, dim=1)
>>> ids_shuffle
tensor([[2, 6, 5, 7, 4, 1, 8, 3, 0]]) # 第0个位置的元素2,表示最小的值是noise中索引为2的0.0854
然后生成恢复索引的 ids_restore和 unmasked x:
>>> ids_keep = ids_shuffle[:, :len_keep]
>>> ids_keep
tensor([[2, 6]]) # 只保留这两个位置的patch
>>> x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D)) # [batch_size, num_patch, dim]
>>> x_masked
tensor([[[2., 2., 2., 2., 2., 2.],
[6., 6., 6., 6., 6., 6.]]])
>>> x_masked.shape
torch.Size([1, 2, 6])
接着计算mask,用于之后只对masked的patch部分计算损失:
>>> mask = torch.ones([N,L])
>>> mask[:,:len_keep] = 0
>>> mask
tensor([[0., 0., 1., 1., 1., 1., 1., 1., 1.]])
>>> mask = torch.gather(mask, dim=1, index=ids_restore)
>>> mask
tensor([[1., 1., 0., 1., 1., 1., 0., 1., 1.]])
接下来看一下解码器的实现:
def forward_decoder(self, x, ids_restore):
# embed tokens,对输入进行embedding操作
x = self.decoder_embed(x)
# append mask tokens to sequence
# 给每个mask掉的patch生成对应的mask_token,是可学习的参数
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # no cls token,这里表示不使用class token参与恢复顺序的计算
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle,恢复顺序
x = torch.cat([x[:, :1, :], x_], dim=1) # append cls token # 再次拼接class token
# add pos embed
x = x + self.decoder_pos_embed
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x
基本上对MAE已经介绍完毕了,整体思路还是比较清晰的,因为对模型没有做过多的修改,因此重点是使用自监督预训练的策略,比较复杂的地方是shuffle和unshuffle操作,其他地方都比较好理解。不过作者添加了蛮多设计在,例如对mask tokens的设计、只在mask patch的部分计算损失等等,总之论文中还有非常多的设计细节值得进一步思考。
之后出现了很多基于ViT和MAE的基础模型(例如Segment Anything Model)等,未来有机会再介绍。
(ps:写博客真的好烧脑…什么时候输出能变成一种自然而然的习惯