最近阅读和自己研究方向比较相近的几篇论文时,其中均使用了SENet和CBAM中的模块,分别是Momenta与牛津大学的《Squeeze-and-Excitation Networks》和韩国科学技术院的《CBAM: Convolutional Block Attention Module》,这两篇工作的思路都比较清晰直观,并且后者是对前者的改进。这两项工作的核心都是一个“即插即用”的模块,因此笔者对两篇工作进行简单地总结和分析,尽可能在原论文的基础上加入自己的理解。
SENet
CNN中的卷积块提取特征时,融合了空间和通道中的信息,是一种“局部感受野”。这篇工作中,作者更加关注不同通道之间的关系,因此设计了全新的网络块——Sequeeze-and-Excitation Block(压缩-激励块):将每个通道的信息压缩为一个数字,多个通道压缩后的数字输入全连接神经网络来显式建模通道之间的依赖关系,网络的输出作为激励与原始对应的通道相乘,从而激励网络关注更加重要的通道,本质是一种通道注意力。这个SE块的特点主要有:
- 显式建模通道的依赖关系:将每个通道压缩、计算为一个数值,其数值直接反映该通道的重要程度;
- 自适应校准通道响应:全连接神经网络中的参数可学习,因此通道响应可以不断更新;
作者在ILSVRC上进行实验,取得了当年的SOTA,在其他的任务上也实现了通过很小的额外计算成本带来显著的性能提升的效果。下面介绍一下SENet的核心结构——SE-block。
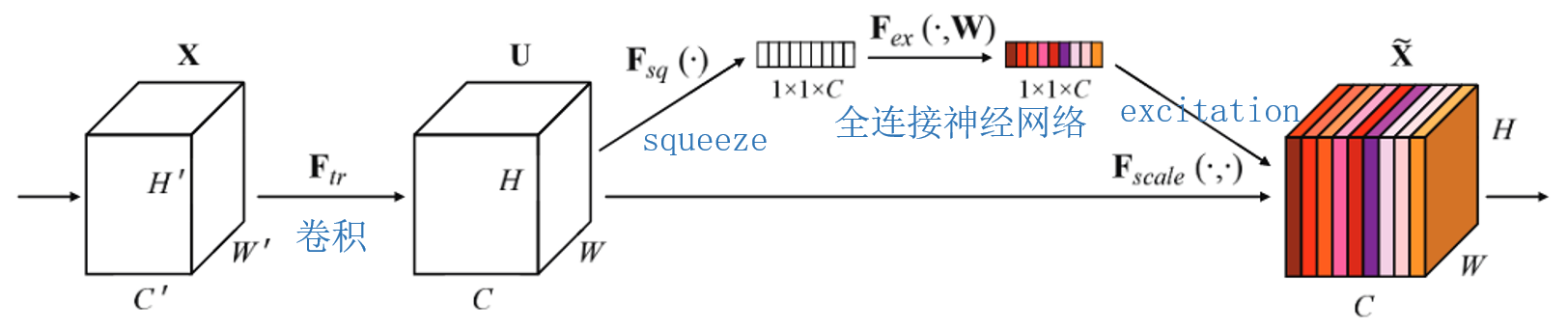
- 特征图X首先经过卷积操作得到U;
- 对U进行挤压squeeze操作,将每个通道的信息通过一个数值表示(也就是不同通道的权重),论文中使用全局平均池化实现;
- 接着将C个通道的权重输入全连接神经网络,通过网络学习自适应调整权重,也就是让网络学习不同通道的贡献;关于全连接神经网络的设计放在下文讨论;
- 得到的新的权重与U进行乘积计算(即对不同通道进行excitation),从而完成特征图通道维度的重标定;
从这个过程中看到SE-block作为“即插即用”的模块,可以灵活地添加到网络的不同阶段,并且在不同阶段的作用不同:前期特征图为低级特征,因此SE-Block学习更通用的特征;后期特征图为高级特征,因此SE-Block学习任务相关的特征,使得网络在分类决策时对关键通道更敏感。
作者在不同的任务和不同的模型上进行了实验,验证了SE-Block的有效性和灵活性。
细节1:学习通道权重的全连接神经网络
要求:
- 可学习,捕获不同通道之间的非线性关系;
- 非互斥关系:多个通道之间应该不是互斥关系,即防止出现one-hot使得其他通道的信息丢失;
因此作者设计了两层神经网络,输入和输出维度相同(为C),隐藏层维度为C/r(r是SE-Block中重要的超参数),sigmoid函数作为最终的激活函数。
\[s = sigmoid(W_{2} * ReLU(W_{1} * z))\]代码实现
SE-Block的设计,实现还是比较简洁的。
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
"""
x: [B, C, W, H]
return: [B, C, W, H]
"""
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c) # [B, C, W, H] -> [B, C]
y = self.fc(y).view(b, c, 1, 1) # [B, C] -> [B, C, W, H]
return x * y.expand_as(x) # [B, C, W, H] 通道乘法
将SE-Block堆叠在网络中,下面的例子中将SE-Block放在了网络的后半部分,并且注意到这个模块应该放在卷积操作之后。
def forward(self, x):
residual = self.downsample(x) # [B, C, W, H]
out = self.conv1(x) # [B, C, W, H] -> [B, C, W, H]
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out) # [B, C, W, H] -> [B, C, W, H]卷积后进行
out += residual
out = self.relu(out)
return out
总结
简单来说SENet是一种通道注意力,通过自适应通道权重并对不同通道进行重标定,引导网络关注更加重要的通道。CNN中的卷积同时融合通道维度和空间维度的信息,而SENet对通道之间的关系进行显式建模。
作为一个即插即用的模块,SE-block可以灵活地添加在网络中不同的位置,以期提升模型效果,未来笔者会尝试在网络的不同位置添加SE-Block来对比效果的差异。而在多模态学习,把不同模态的数据放在多个通道,那么引入SE-Block就可以使得网络关注更加重要的通道。
CBAM
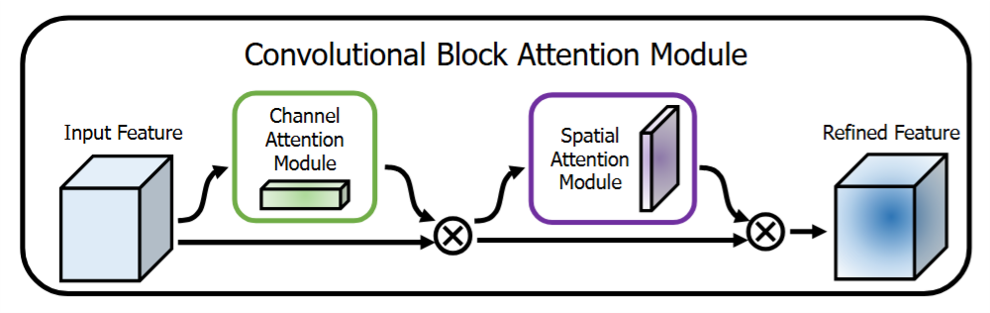
和SE-Net相似,论文作者也提到了传统的CNN卷积块同时提取空间和通道信息。不同的是SE-Net仅关注通道关系的建模,而这篇工作中作者提出Convolutional Block Attention Module(CBAM,卷积块注意力模块),依次对通道和空间信息进行显式建模,使得网络在通道和空间两个维度学会关注什么、关注哪里,本质上是通道注意力+空间注意力。
在SE-Block的基础上,作者主要有两个方面的改进:
- 将SE-Block的”squeeze”操作中的全局平均池化替换为全局平均池化 + 最大池化;
- 添加空间注意力机制。
CBAM的结构见下图,输入的特征首先与通道注意力权重进行计算,接着和空间注意力权重进行计算(也就是说通道注意力和空间注意力是串行计算的,作者设计了并行计算、先空间后通道的串行计算实验,结果显示先通道后空间的串行计算方式效果最优),最终得到重标定的特征图。
通道注意力模块
CBAM中的通道注意力模块是在平均池化的基础上,添加了一个并行的最大池化以获得更加精细的注意力(平均池化和最大池化得到的注意力权重共享相同的MLP层),结构图见下:
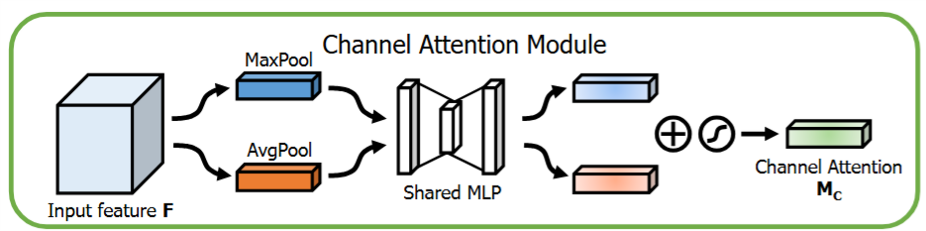
通道注意力模块可以直接表示为:
\[M_{channel}(F) = sigmoid(MLP(AvgPool(F)) + MLP(MaxPool(F)))\]空间注意力模块
空间注意力模块在通道注意力之后,其解决的问题是“关注哪里”,模块结构示意图见下:
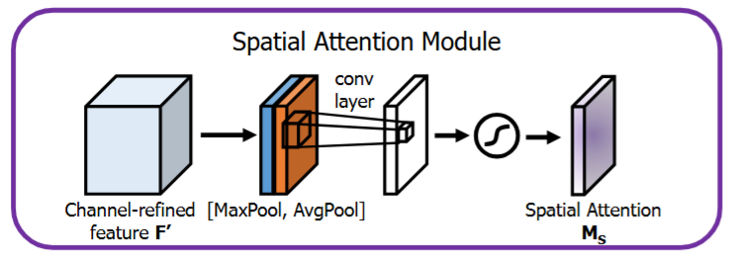
通道注意力重标定后的特征经过最大池化、平均池化得到空间初始权重,进行卷积操作后得到单通道融合权重,最后经过激活函数得到空间注意力权重。
从特征图F得到空间注意力权重的过程可以描述为:
\[M_{spatial}(F) = sigmoid(filter^{7*7}(AvgPool(F);MaxPool(F)))\]代码实现
首先是通道注意力模块的实现,其中MLP的隐藏层的神经元个数为超参数(reduction_ratio决定)。
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']): # 平均池化和最大池化
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio), # reduction_ratio代表隐藏层维度压缩的比例,重要的超参数
nn.ReLU(),
nn.Linear(gate_channels // reduction_ratio, gate_channels)
) # 平均池化和最大池化得到的通道权重共享一个MLP
self.pool_types = pool_types
def forward(self, x):
channel_att_sum = None
for pool_type in self.pool_types:
if pool_type=='avg':
avg_pool = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( avg_pool )
elif pool_type=='max':
max_pool = F.max_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( max_pool )
elif pool_type=='lp':
lp_pool = F.lp_pool2d( x, 2, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp( lp_pool )
elif pool_type=='lse':
# LSE pool only
lse_pool = logsumexp_2d(x)
channel_att_raw = self.mlp( lse_pool )
if channel_att_sum is None:
channel_att_sum = channel_att_raw
else:
channel_att_sum = channel_att_sum + channel_att_raw # 几种池化操作得到的通道权重元素级相加
scale = F.sigmoid( channel_att_sum ).unsqueeze(2).unsqueeze(3).expand_as(x) # 激活函数作用
return x * scale # 通道重标定
接着是空间注意力模块的实现,其中比较重要的超参数是卷积操作的卷积核大小。
class ChannelPool(nn.Module): # 最大池化和平均池化
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7 # 池化操作得到的结果需要进行卷积,从2-channels -> 1-channel
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x) # 池化操作
x_out = self.spatial(x_compress) # 卷积操作,变为单通道
scale = F.sigmoid(x_out) # broadcasting,激活
return x * scale # 空间重标定
然后是 CBAM模块的实现, forward函数中的 if是消融实验时用到的。
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max'], no_spatial=False):
super(CBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
self.no_spatial=no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x) # 通道注意力
if not self.no_spatial: # 空间注意力,参数为false时进行该模块的消融实验
x_out = self.SpatialGate(x_out)
return x_out
最后来看一下 CBAM模块如何添加在网络,下面是 ResNet的一个模块的设计,CBAM位于特征提取的后部分,实际上我觉得随着 RES-Block的堆叠, CBAM的通道注意力和空间注意力也会累积。
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, use_cbam=False):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
if use_cbam:
self.cbam = CBAM( planes, 16 )
else:
self.cbam = None
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
if not self.cbam is None: # 可以看到CBAM模块是在该模块特征提取的后部分
out = self.cbam(out)
out += residual
out = self.relu(out)
return out
小结
SE-Block和CBAM模块的思想和实现都比较简单直观,额外的计算量小而效果显著。作为即插即用的模块,可以方便地添加在任意网络的任意位置,得到了广泛的应用。
笔者最关注的还是这两个模块在多模态学习中的应用,未来会继续讨论目前多模态学习领域中如何应用这两个模块来解决问题。