背景
当神经网络越来越深时,靠近loss的层(高层,提取高级语义信息)参数梯度较大,更新较快,但是靠近data的层(底层,提取低级语义信息,例如边缘)参数梯度很小,更新很慢;然而低层的变化会使得高层参数重新训练,导致模型收敛速度很慢,因此考虑学习底层特征时,避免高层参数不断变化。
另一个解释是通过BN让数据更加规整,将其调整到激活函数敏感的区域,可以帮助模型更好地学习内部范式。
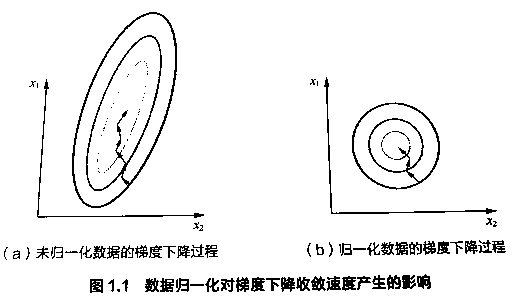
还有更常见的解释是将feature scaling,让特征的每个维度分布比较均衡,这样会帮助模型找到一个好的梯度方向。
核心idea
设置固定的分布,使得数据经过特定层后,保持这个分布不变,从而影响模型参数的学习。
固定小批量的均值和方差:
Step1 : 计算Batch均值和方差
\[\mu_{B}=\frac{1}{|B|}\sum_{i\in B}x_{i} \ and \ \sigma^{2}_{B}=\frac{1}{|B|}\sum_{i \in B}(x_{i}-\mu_{B})^{2}+\epsilon\]Step2 : 额外调整,固定分布
\[x_{i+1}=\gamma \frac{x_{i}-\mu_{B}}{\sigma_{B}}+\beta\]其中 ($\gamma$)为方差,($\beta$)为均值,均为可学习参数;而使用反向传播算法更新参数时,也需要考虑均值 ($\mu$)和方差 ($\sigma$)的影响(因为是 ($x$)计算得到的统计量,并不是简单的常数)
作用
BN调整分布的地方:
- 全连接层和卷积层输出上,在激活函数前
- 全连接层和卷积层输入上
- 对于全连接层,作用在特征维
- 对于卷积层,作用在通道维(最终通道维为n,其他维为1)
最初论文认为BN的作用是减少内部协变量偏移,但之后论文指出实际是BN为模型加入噪音(因为使用随机小批量数据计算均值 ($\hat{\mu}_{B}$) 和方差 ($\hat{\sigma}_{B}$).
可以加快模型收敛速度,但一般不改变模型精度,一般在training不好时有用。
参数 ($\beta$)是prameter,随着模型的训练不断更新。在模型的inference阶段,会使用训练数据上得到的 ($\hat{\mu}$)、($\hat{\sigma}$)、($\gamma$)、($\beta$)来对新的数据进行BN。
代码实现
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
if not torch.is_grad_enabled(): # inference
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in(2 , 4)
if len(X.shape) == 2:
mean = X.mean(dim=0)
var = ((X - mean)**2).mean(dim=0)
else:
mean = X.mean(dim=(0, 2, 3),keepdim=True)
var = ((X - mean)**2).mean(dim=(0, 2, 3), keepdim=True)
X_hat = (X - mean) / torch.sqrt(var + eps)
moving_mean = momentum * moving_mean + (1 - momentum) * mean # 靠近结束的参数更精确
moving_var = momentum * moving_var * (1 - momentum) * var
Y = gamma * X_hat + beta
return Y, moving_mean.data, moving_var.data
pytorch中使用:
nn.BatchNorm2d(num_features= , eps=,momentum= ,affine= , track_running_stats= )
局限
上面提到在模型的inference阶段,对new data进行BN操作时使用的是训练数据中得到的均值 running_mean和方差 running_var,并且可学习参数 gamma和 beta是适用于训练数据的,当推理时数据和训练数据之间的分布存在明显差异时,反而会影响模型的性能