简介
OCTA-500是在作者之前的IPN工作基础上展开的,作者为南京理工大学的陈强教授团队,论文发表在MIA期刊(医学图像领域顶刊,中科院一区),论文开源的OCTA-500是目前数据规模最大的OCTA数据集。
其中关于数据集制作的描述可以为之后构建相关数据集提供参考,特别是关于利用血管自身的特性从大血管中划分出动脉和静脉、划分毛细血管以及得到中央凹无血管区FAZ的3D标签(关于FAZ体积涉及到作者的另一篇工作,除此之外论文中的多任务学习也为之后设计模型提供了很好的参考。
摘要Abstract
光学相干断层扫描成像OCTA作为新的成像方式,可以观察到视网膜血管和微血管系统,已经被广泛用于眼科和神经科学研究,但目前开源的OCTA数据非常少。这篇论文中,作者介绍了目前最大并且最全面的OCTA数据集,名为OCTA-500,其中包括数据:
- 2个视野FOVs:包括OCTA-3mm、OCTA-6mm,即以中央凹为中心扫描的半径
- 500个样本:来自500个受试者的数据
- 2种模态:OCT、OCTA,OCT主要反映眼底组织结构,OCTA在OCT的基础上通过特殊方法获得(常使用分振幅去相关造影,SSADA算法),反映眼球中的血流信号
- 6种类型投影:在OCT和OCTA数据上,以内界膜、外丛状膜、BM膜为划分,选择平均或最大投影方式得到6种类型的投影
- 4种文本标签:年龄、性别、眼睛左右、患病情况
- 7种类型分割标签:大血管、毛细血管、动脉、静脉、2D FAZ、3D FAZ、视网膜层
接着作者提出新的多类别分割任务为CAVF,在一个分割框架下实现毛细血管capillary、动脉artery、静脉vein、中央凹无血管区FAZ的端到端分割。此外作者优化了3D-to-2D网络 IPN为IPN-V2。实验数据表明IPN-V2在CAVF任务上的mIoU相较IPN网络提升了10%。
最后作者讨论了一些数据集特征对分割效果的影响(包括训练集大小、模型输入模态、baseline模型和图像的疾病属性)。
1 引言Intro
光学相关断层扫描OCT可以无创获得视网膜的3D结构数据,局限性在于不能直接提供血流信息。在OCT基础上,OCTA通过特殊方法德奥血流信息从而重建视网膜血管结构,于2014年投入临床应用并显示出优越性。
对OCTA数据进行定量分析很重要,例如血管密度、血管直径指数、血管分形维度、中央凹无血管区FAZ面积、FAZ周长等,从OCTA图像中分割血管结构是进行定量分析的前提。目前有相当多的方法用于OCTA数据的量化分析。
数据在计算机视觉任务中起着决定性作用。目前OCTA数据相当少,成为影响OCTA量化分析的主要挑战。作者整理了4个公开可用的OCTA数据集,存在的问题包括:
- 图像数量和疾病多样性不足
- 数据集为单一模态,仅包含OCTA投影图
- 数据集为单一任务数据集,仅提供单一类型标签
- 最新的研究焦点(例如3D FAZ分割、动脉-静脉分割)无可用数据集
因此作者提供了一个新的数据集:OCTA-500,相关介绍见上文,OCTA-500是目前最大、最全面的OCTA数据集。
在OCTA-500数据集的基础上,作者提出一种在同一框架下实现多任务学习的任务CAVF,包括毛细血管、动脉、静脉、FAZ分割。在CAVF任务基础上,使用2D分割网络作为baseline,并且考虑了3D-to-2D的分割方法即图像投影网络IPN(作者之前的工作,基本思路是直接利用OCT/OCTA得到的3D图像序列数据完成分割任务,而不是先得到图像序列数据投影后的2D数据,再进行分割),并且再IPN的基础上优化了网络结构为IPN-V2。
在OCTA-500数据集上的一系列实验,提出了几个问题:
- 一定训练数据的数量的增加会是深度学习方法提升多少?
- 不同模态数据的输入如何影响分割质量?
- CAVF任务上哪些baseline表现好?
- 在不同的疾病情况下,分割模型标签如何?
2 相关工作 Related Work
2.1 OCTA 数据集
目前可用的OCTA数据集如下,汇总了数据集中的数据模态、样本数、患病情况、投影数量、文本标签数据、体积信息、分割标签、FOV视野大小、图像尺寸。
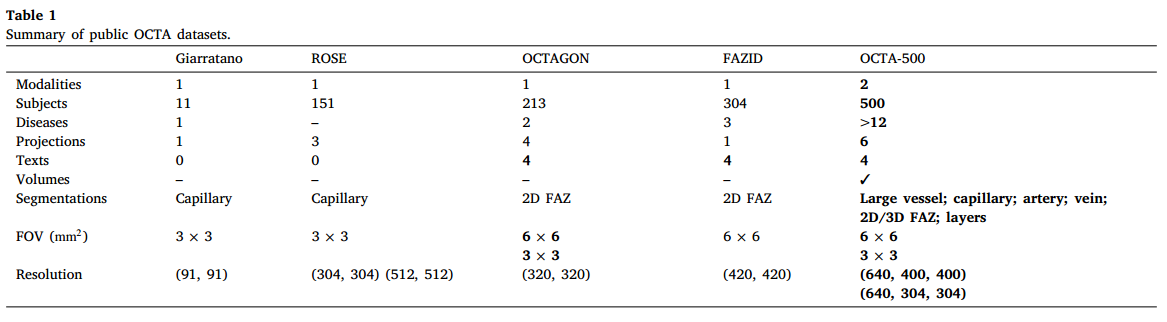
Giarratano和ROSE用于血管分割,OCTAGON和FAZID用于FAZ分割,这些数据集仅关注某一特定的任务。并且只包含OCTA单一模态的数据。
疾病多样性可以反映出不同方法的泛化性,上面表格中可以看出OCTA-500数据集的多样性。
2.2 血管分割
- 阈值法
OCTA图像中血管比背景有更高的信号强度,因此阈值法可以容易地划分出背景和血管。但阈值法一个明显的缺点是对于背景噪声无法容忍
- 滤波法
滤波被用于对血管进行增强,然后使用不同的基于阈值的方法获得血管二值图像,可以粗略地分割血管来估计血管密度,但当存在伪影、运动模糊、弱对比度、低分辨率和疾病的情况下,分割效果通常很差;同时对于毛细血管、静脉、动脉缺乏足够的识别能力
- 基于主动轮廓模型
- 深度学习方法
UNet是典型的encoder-decoder结构;CS-Net提出空间注意模块和层注意力模块;OCTA-Net提出两个阶段来分别完成粗血管和细血管的检测;但都在2维投影上进行分割,生成依赖精确的层分割
IPN是从3D OCTA体积中分割出2D大血管的3D-to-2D分割方法,不使用层分割来生成2D投影图,最近PAENet在IPN的基础上添加四重注意力模块和双向投影学习
AV-Net用于分割OCTA中的动脉/静脉,在AV-Net基础上开发MF-AV-Net;
但由于OCTA缺乏动脉/静脉注释,因此没有得到广泛发展
2.3 FAZ分割
中央凹无血管区FAZ,被视网膜血管包围,是视觉最敏感的部位;FAZ大小与视力和疾病高度相关;FAZ分割中的特征可以提升多疾病分类性能
近十年主要使用荧光血管造影FA方法对FAZ进行分析
OCTA可以对FAZ进行无创检查、可视化和定量分析
- 无监督方法
根据FAZ位置特征(位于图像中心)、几何特征(唯一连通区)、灰度特征(无血管)设计,通常需要设置初始种子或初始轮廓;
可以在健康或单一疾病的小型数据集上表现较好性能,但在更大更复杂的数据集上会困难
- 监督方法
UNet、Mask R-CNN对OCTA图像进行FAZ分割,但是在2D OCTA图像上完成的
IPN可以实现3D-to-2D的分割
2.4 主要贡献
- 介绍OCTA-500数据集,包含从500个样本的2个视角,包括2个模态、6种投影、4个文本标签、7个分割标签
- 提出CAVF任务,在一个框架下完成动脉、静脉、毛细血管和FAZ分割;在此基础上将IPN优化为IPN2
- 关注数据集特征:训练集尺寸、模型输入、baseline和疾病
3 OCTA-500数据集
介绍数据采集过程和OCTA-500的两个子集;介绍OCTA-500中包括OCT/OCTA、投影图、文本标签、分割标签的内容;
3.1 数据收集
OCTA-6mm包含300个样例,NO.10001-NO.10300,视场为6mm×6mm,主要来自患病人群,正常人群占少数;
OCTA-3mm包含200个样例,NO.10300-NO.10500,视场为3mm×3mm,主要来自正常人群,其次是患病人群;
3.2 OCT&OCTA 模式
补充:
OCTA图像通过SSADA算法从OCT图像中得到,原理:静止的眼球中,眼底唯一运动的结构是血管里流动的血细胞,对同一横断面的重复扫描,通过特殊方法,对比静止性结构和活动性结构,从而获得血流信号,据此进行血管结构的三维重建
SSADA 分振幅去相关造影法

OCT/OCTA实际得到的图像是对眼球进行2D扫描得到的横截面,通过对每个样例进行304次(OCT)和400次(OCTA)扫描来展现其3D结构。
3.3 投影图
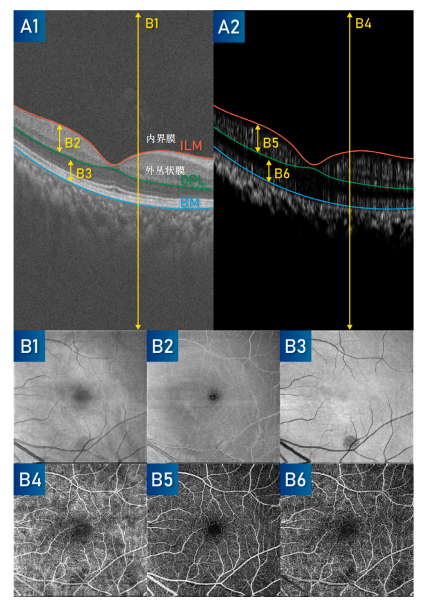
OCT/OCTA模式可以实现通过层分割得到不同的投影层,论文中提供了6种类型的投影图,在OCT和OCTA分别按照ILM、OPL和BM膜。投影图的通过轴向平均或最大化得到,OCT反映血管结构,通常使用平均投影,OCTA反映血流信号强度,通常使用最大投影。
- B1:OCT全投影,计算轴向平均值,显示OCT全局信息
- B2:ILM内界膜和OPL外丛状层之间的平均投影,视网膜内血管
- B3:OPL外丛状层与BM膜之间的OCT平均投影,血管对比度高于B2
- B4:OCTA全投影,沿OCTA轴向平均值,视网膜和脉络膜的整体视野
- B5:OCTA在ILM内界膜和OPL外丛状膜之间的最大投影,清楚显示内视网膜血管形态和FAZ形状
- B6:OCTA在OPL外丛状膜和BM膜之间的最大投影,观察CNV脉络膜新生血管的形态
3.4 文本标签
对4种文本标签进行统计:性别、左右眼、年龄、疾病
3.5 分割标签
| 分类 | 结构特性/应用 | 难点 | 方法 |
|---|---|---|---|
| 大血管 | 血管密度评估视网膜疾病、作为掩膜去除伪影来分割出毛细血管 | 阈值二值化难以区分出毛细血管和噪声 | 使用Photoshop软件对OCTA视网膜内投影B5中的大血管打标签 粗粒度标注:追求没有遗漏的血管,不要求精确边界 细粒度注释:Screen模式,对边界进行精细划分 |
| 动静脉 | 动静脉鉴别可为诊断眼科疾病提供有价值信息 | 仅使用OCTA图像来标记动静脉非常困难 | 参考多种成像方式:彩色眼底图像、OCT、OCTA 1.彩色眼底图像确定主要血管的动静脉分类(其视野更宽、具有颜色信息) 2.识别OCTA视网膜内投影B5和B3中血管交叉点和分支点来划分动静脉 交叉:4支,颜色较深,血管性质不同(通常为1静脉+1动脉) 分支:3支,颜色较一致,血管性质一致 使用私有数据集训练模型,模型输入为彩色眼底、OCT/OCTA图像,输出为动静脉分割 |
| 毛细血管 | 密集网状结构 | 图像分辨率有限、存在噪声 已有的方法进行骨架级分割skeleton-level |
裁剪、像素级标注,得到切片和标注后切片 使用图像放大网络IMN,可以捕捉图像细节,滑动窗口得到整体结果 但存在噪声(FAZ,可能与缺乏全局信息有关)、毛细血管拓扑清晰度有待提高 1.使用FAZ掩码去除FAZ区域噪声 2.最近提出的标签对抗学习LAL增强血管拓扑结构,实现骨架级到像素级血管分割 3.手动校对 |
| FAZ | 血管丛在中央凹边缘形成的、无毛细血管区 已被确定与视力和疾病有关 |
3D结构 目前FAZ主要在投影图上进行2D分割来计算面积等指标 |
作者近期工作给出FAZ的3d定义 2D FAZ:在OCTA视网膜内投影上进行2D FAZ分割,参考原则, 最近对FAZ标签进行优化,毛细血管标记后发现FAZ边界与毛细血管丛并不完全吻合 提出基于毛细血管标签的FAZ边界的像素级优化 3D FAZ:根据2D上的原则,在每个2D横截面上标注FAZ区域, 最终将所有2D标签融合得到3D FAZ标签 |
| 视网膜层 | 在OCT/OCTA中分析结构的重要工具,视网膜厚度分析、 不同层上的血管密度统计、投影图生成均依赖层分割 |
疾病可能影响/破坏视网膜层,因此视网膜层有复杂和多样结构 使得疾病条件下视网膜层分割算法设计更具挑战 |
层分割标签:ILM内界膜、IPL内丛状膜、OPL外丛状膜、 ISOS、RPE视网膜色素上皮、BM膜 通过软件得到初步结果,然后由专家校正 3种类型液体影响层结构,根据定义手动调整, 层分割算法为作者之前的工作 |
4 CAVF任务&基线模型
4.1 CAVF任务
在同一框架下实现毛细血管、动脉、静脉、FAZ分割
(1)之前的研究关注单一分割任务,单一任务模型的训练不方便;我们提出的多目标分割任务统一了几个关联的分割任务:
FAZ被毛细血管环绕;动静脉相斥。多目标分割任务允许模型解决多个分割问题,减少计算量
(2)多目标分割融合单独分割的特征,提供更加全面的评估
4.2 基线模型
2D-to-2D baseline
U-Net、UNet++、UNet3+、Attention UNet、CE-Net、CS-Net、AV-Net、VC-Net、ViT、UNETR
UNet在医学图像分割领域最常用,并且被证明使用少的样本即可实现快速和高精度,OCTA分割方法在其基础上改进,例如UNet++、UNet3+、Attention UNet
血管分割、动静脉分割,CE-Net、CS-Net、AV-Net、VC-Net
tansformer:ViT、UNETR
3D-to-2D baseline
图像投影网络IPN,输入3D OCT/OCTA,输出2D分割结果
- 不依赖层分割,避免疾病条件下层分割失败
- 充分利用3D信息,减少信息损失、提高分割精度
优化IPN结构为IPN-V2,IPN的缺点:计算资源有限对图像进行切割,丢失全局信息;IPN在水平方向没有下采样,缺少高级语义信息。对IPN结构进行修改:大的3D空间的卷积低效:OCT/OCTA包含大量背景,但不要在这些位置提取特征,因此考虑将3D信息快速压缩为2D,减少计算,接着在提取的2D特征中进一步分割。
3D-to-2D投影:目标为快速将3D信息压缩到2D空间,设计快速投影单元FPM。包括4个下采样(3个不同尺度的卷积和IPN中的单向池化)。多尺度卷积用于提取有用特征,单向池化用于压缩特征。
FPM输入(H,L,W),输出(H/h,L,W),其中h为压缩系数
2D分割:理论上可以是使用任意2D卷积网络;设计编码器-解码器结构,其中多尺度语义特征可以解决IPN缺乏高级语义信息的缺点
4.3 评价指标
Dice、IoU、ACC、SE、SP
5 实验
5.1 实验设置
| 训练 | 验证 | 测试 | |
|---|---|---|---|
| OCTA-6mm | 240 | 10 | 50 |
| OCTA-3mm | 140 | 10 | 50 |
损失函数:交叉熵损失L_CE、Dice损失L_DICE,L=L_CE+L_DICE
优化器:Adam
batchisze:4
lr=0.0005
5.2 训练数据数量
探索训练数据增加时分割质量怎样变化,2D-to-2D baseline为UNet,输入为全投影图,3D-to-2D baseline为IPN-V2,输入为OCTA,在相同的测试集上评估

- 随着训练样本增加,mIoU先增大后区域稳定;对于OCTA-6mm,在样本120时稳定;对OCTA-3mm,在样本80处稳定,因此数据集满足要求
- OCTA-3mm性能优于6mm,可能由于分辨率高、疾病率低
- OCTA-6mm比OCTA-3mm需要更多样本才能稳定,也与其包含更多疾病样本有关
- 动静脉和FAZ与mIoU趋势相似,而毛细血管对数据需求低,因此该任务更容易
- 样本数少时,UNet比IPN2效果更好;样本数多时,IPN2更好,尤其是在毛细血管分割,3D-to-2D去除噪声影响;3D-to-2D比2D-to-2D需要样本数更多
5.3 输入数据的类型
对于2D-to-2D网络,选择不同的投影图及组合;对于3D-to-2D网络,选择不同的3D数据

- 2D-to-2D:B1-B6投影效果最好,B4-B6仅差0.1,说明OCTA提供信息更重要
- 3D-to-2D:仅使用OCTA更好,OCT反而影响模型效果
5.4 不同baseline对比
定量对比:
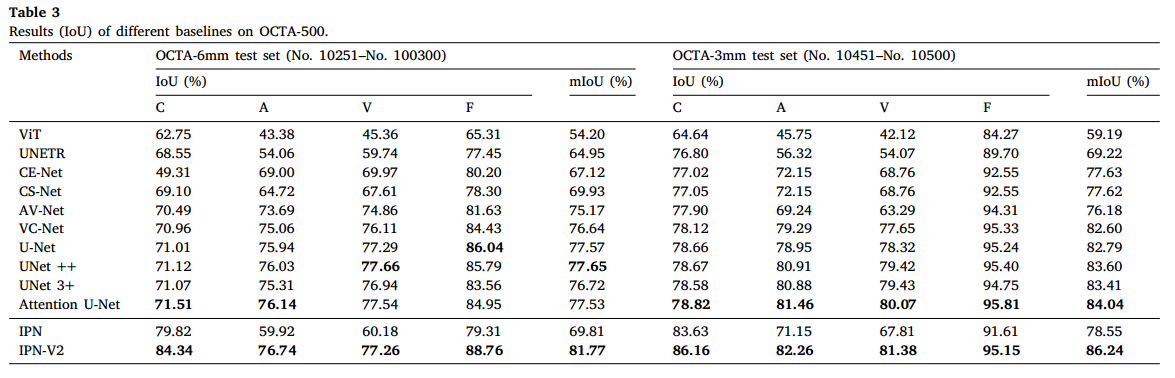
- UNet及变形等网络比AV-Net、CS-Net更好,可能因为后者为单任务设计,不能泛化到CAVF任务
- 基于tansformer的ViT、UNETR效果最差,可能由于tansformer训练需要大量数据
- 2Dbaseline中Attention UNet最好,说明注意力机制可以提升该任务的性能
- 所有模型中IPN-V2最佳
定性对比:
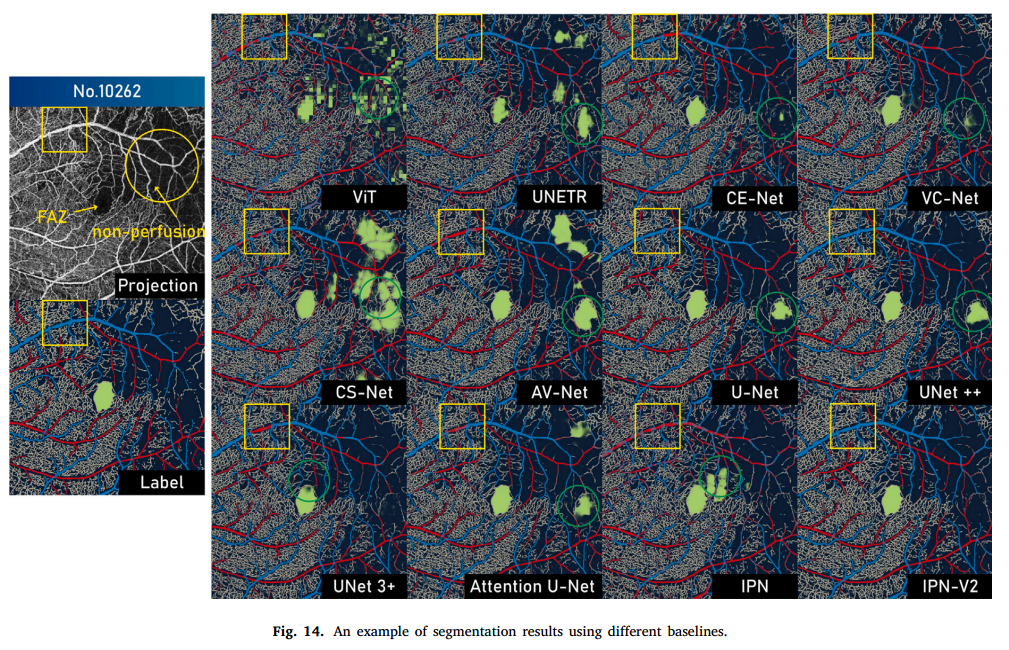
- FAZ分割除IPN-V2外,均表现出过分割或欠分割
- 动静脉分割中,同一血管的不同部位容易被错误划分为不同类别,IPN-V2表现更好,但没有完全解决
5.5 不同疾病表现
验证不同疾病下的分割表现,在6mm数据集上使用IPN-V2进行3折交叉验证
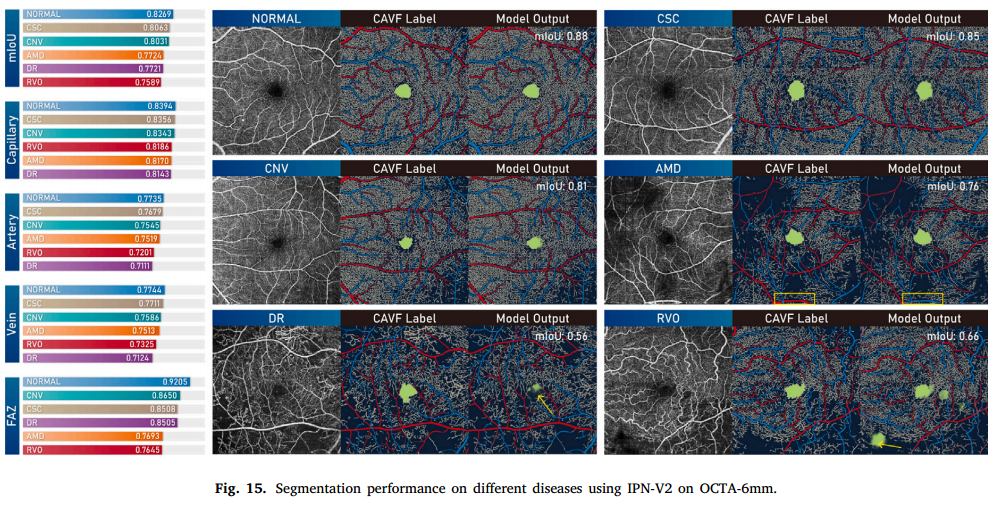
- 正常图像得到最佳分割结果,说明可以获得可靠结果;患病的表现较差,尤其是AMD、DR等伴随形态改变
6 讨论
CAVF任务不仅优化和评估算法,而且可以提供多样的视网膜图像量化和评估方法
OCTA数据集提供多种标签,多模态数据的更多应用值得被研究
7 总结
- OCTA数据集,CAVF任务,在此任务上优化IPN-V2网络,探索数据量、输入数据的类型、baseline模型和疾病条件下的分割表现
- 数据规模而言,OCTA数据集数据量满足需求;IPN-V2提升分割性能;疾病多样性使得分割任务更具挑战
- 讨论OCTA数据集在其他方面的应用